Building an AI and Data Pipeline for Norwegian Parliamentary Procedure

Over the past months, I’ve been working on a project that combines my interests in data-engineering, AI, and civic transparency: building a Contextualise AI-based data pipeline that processes and analyses the procedures of the Norwegian Parliament (Stortinget).
This pipeline is designed as a full ETL (Extract – Transform – Load) workflow and lays the foundation for deeper analysis, including graph-based exploration and AI-driven insights.
Why Parliamentary Data?
Parliamentary procedure is the backbone of a democracy. In Norway, as in other countries, decisions are shaped through debates, committees, amendments, and votes. This process produces a wealth of structured and unstructured data:
- Representatives and their affiliations
- Committees and sessions
- Bills, amendments, and reports
- Voting results
- Transcripts of debates
Yet, while much of this information is technically public, it is not always easy to explore, connect, or analyse. That is where a tailored AI and data pipeline comes in.
Step 1: Extract
The first stage involves collecting data from the Stortinget’s open APIs and other publicly available sources. This includes:
- Metadata about representatives, parties, and committees
- Information about sittings, documents, and proposals
- Full transcripts of debates
- Voting records
The extraction process is automated to run on a schedule, ensuring that the pipeline is always up to date with the latest parliamentary activity.
Click here to see the full-size image.
{kind=link}
Step 2: Transform
Raw data alone doesn’t reveal much. It must be cleaned, structured, and enriched before it becomes useful for analysis. Transformation includes:
- Normalising entity names (for example, ensuring consistency in party names or representative identifiers)
- Structuring debate transcripts into speaker–utterance pairs
- Linking votes to proposals, committees, and representatives
- Adding semantic enrichment: extracting entities, relationships, and themes from text using natural language processing (NLP)
For example, NLP techniques can highlight when certain topics (like housing, healthcare, or climate policy) are discussed, and which representatives or parties are most vocal on those topics.
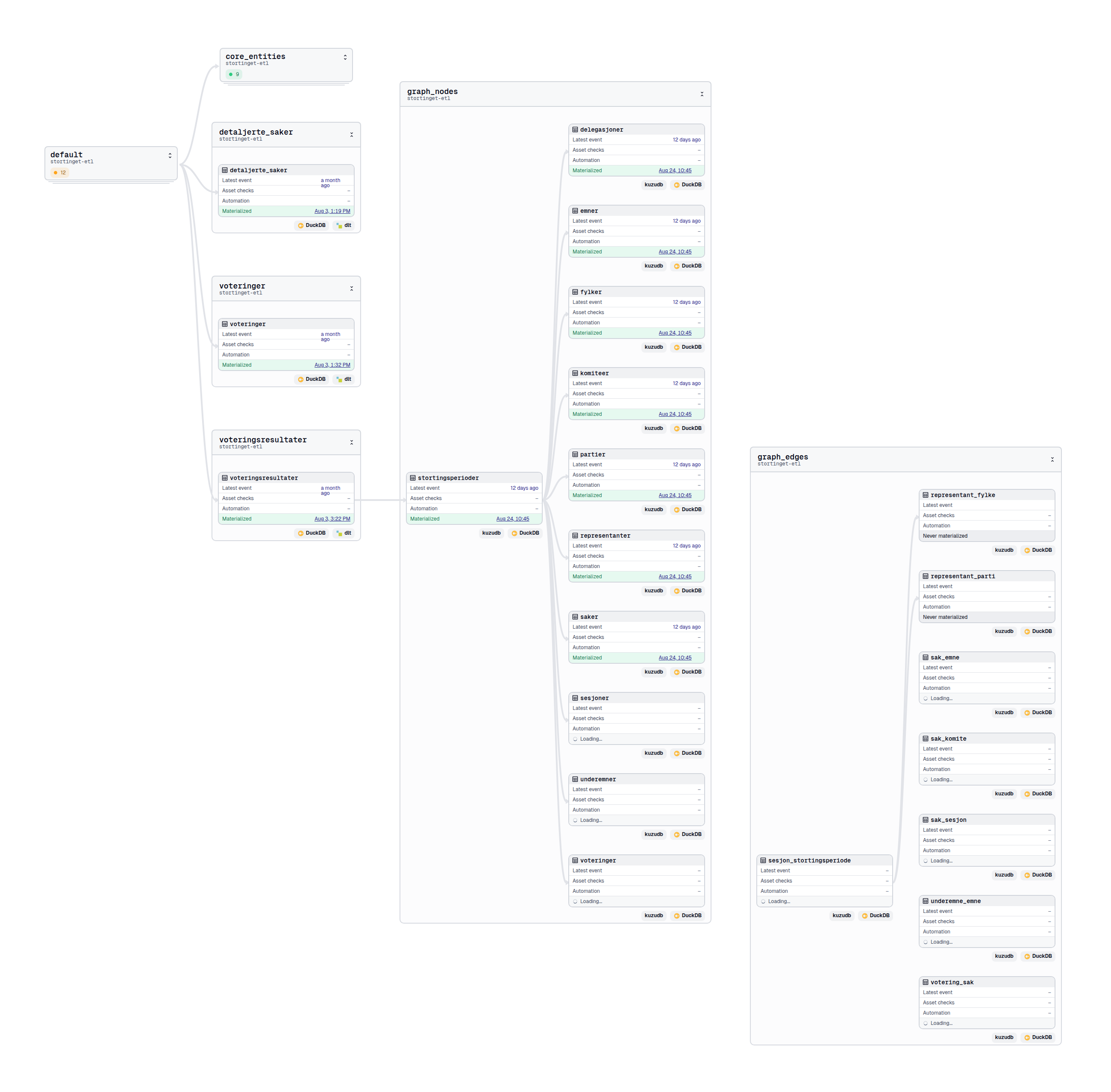
Step 3: Load
Once transformed, the data is loaded into two main storage systems:
This dual-storage approach supports both relational/analytical and graph/network perspectives.
Click here to see the full-size image.
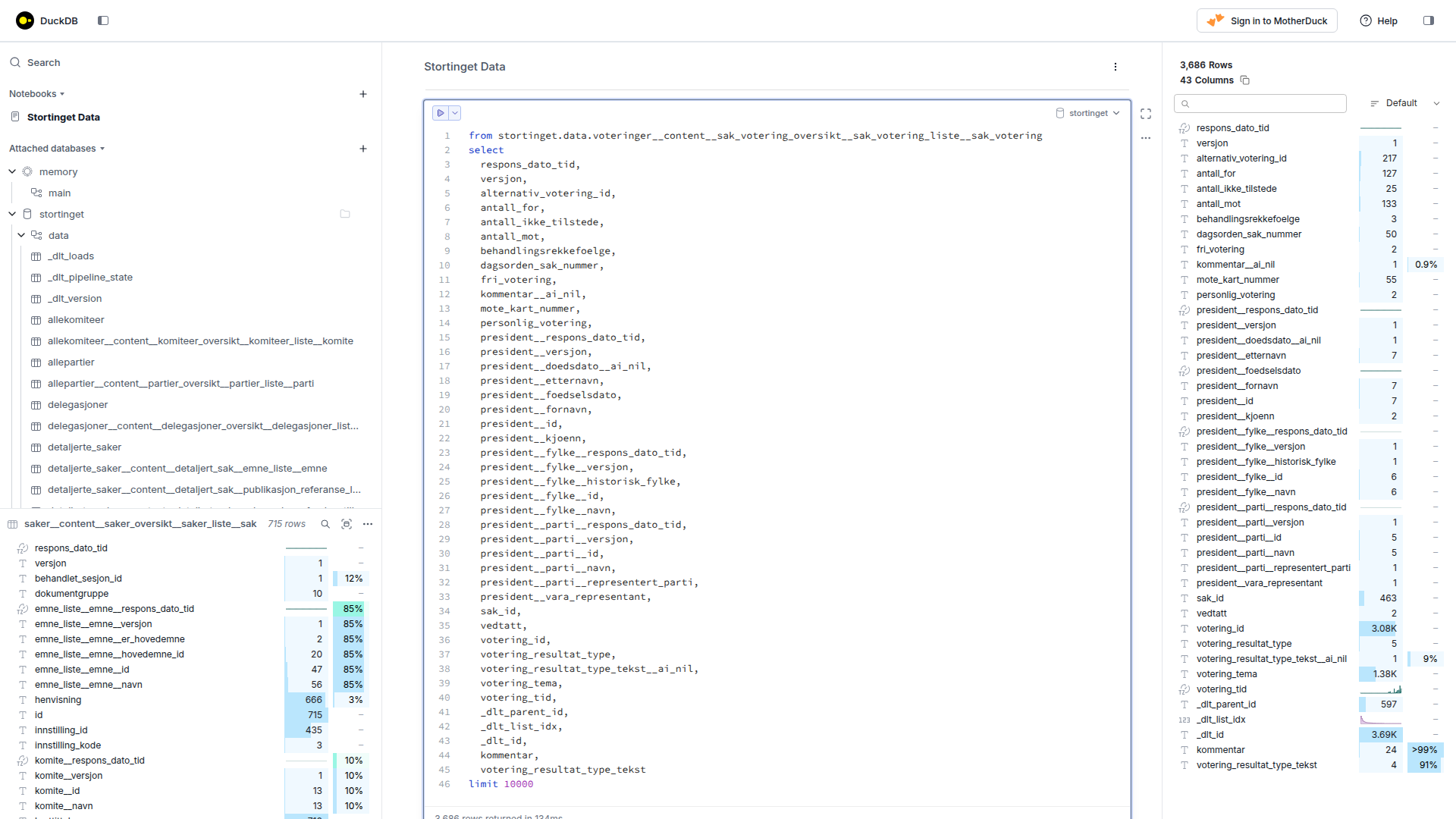
DuckDB, an in-process SQL OLAP database management system; for running scalable analytical queries on numerical data (like voting patterns)
Click here to see the full-size image.
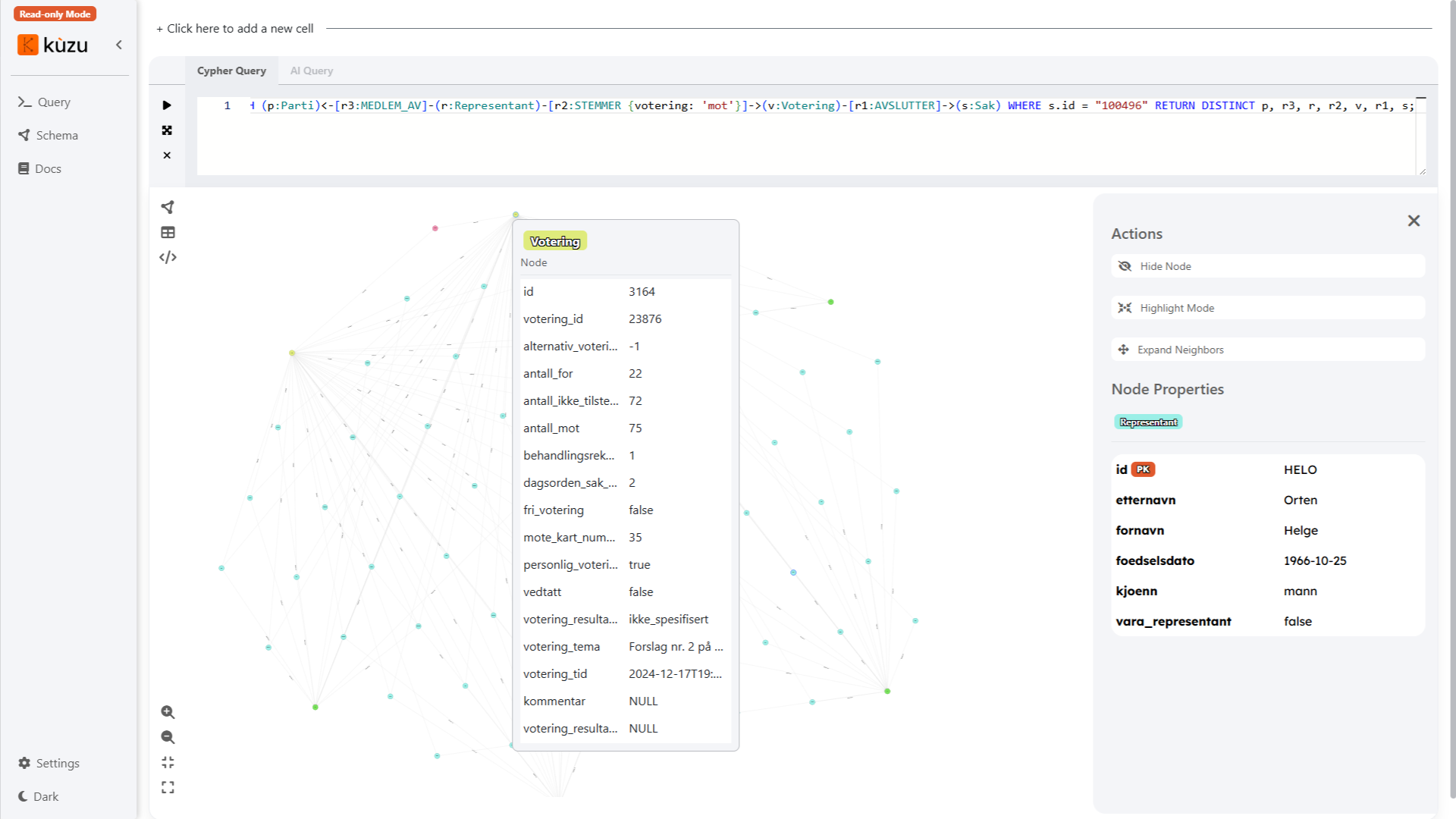
Graph querying and visualization; for capturing complex relationships between representatives, parties, bills, votes, and topics. This makes it possible to run graph queries such as “Which representatives often vote together across different committees?”
In this screenshot above, the (Cypher) query is:
MATCH (p:Parti)<-[r3:MEDLEM_AV]-(r:Representant)-[r2:STEMMER {votering: 'mot'}]->(v:Votering)-[r1:AVSLUTTER]->(s:Sak) WHERE s.id = "100496" RETURN DISTINCT p, r3, r, r2, v, r1, s;Which roughly translates to: return all the representatives and the (political) party that they are a member of which have voted against case (identifier) 100496.
AI-Driven Analysis
With the ETL pipeline in place, the data becomes ready for AI-powered insights. Some directions include:
- Topic modelling: Identifying recurring policy areas in debates over time
- Sentiment analysis: Understanding the tone of debates or speeches
- Network analysis: Mapping alliances and oppositions between parties and representatives
- Anomaly detection: Spotting unusual voting patterns or procedural irregularities
- Entity–relationship extraction with an LLM: Taking a piece of text (for example, a parliamentary debate transcript) and asking the model to identify the entities (such as people, organisations, places, or topics) and the relationships between them (such as “represents,” “belongs to,” “votes with,” or “discusses”). Instead of manually designing rules or training a traditional NLP pipeline, a large language model can understand the context and semantics of the text, making it easier to capture both explicit connections (for example, “Representative A voted for Bill X”) and implicit ones (for example, “The committee expressed support for housing reform”).
By combining AI with structured parliamentary data, we can move beyond raw records to a more dynamic understanding of how political decisions are shaped.
Use Cases
This pipeline can serve multiple audiences:
- Researchers and journalists: A tool to investigate political trends and voting behaviour
- Civic organisations: Transparency into how representatives act versus what they promise
- Citizens: A clearer picture of the debates and decisions shaping society
Ultimately, the aim is to make parliamentary procedures and the resulting data more accessible and understandable to the public.
Next Steps
The pipeline can be expanded in a variety of ways, including but not limited to:
- More advanced visualisations of parliamentary networks and debates
- Full-text and vector-based (semantic) search and recommendation tools for exploring data
- A public-facing dashboard that allows anyone to query and interact with the (numerical) data
- A topic maps-based Contextualise website to navigate and explore the data, especially the extracted entities and the accompanying relationships
This project is still evolving, but the foundation is in place: a working ETL pipeline that transforms raw parliamentary procedure into a resource for analysis, exploration, and AI-driven insights.
You can contact me by email if you have any questions regarding this project: info at contextualise dot dev or via LinkedIn.
Credits
Photo
Peter Mydske/Stortinget - Stortinget Mediearkiv